"Сколько душ прикупать будем?...." О размере выборки в маркетинговых исследованиях
Самым распространенным заблуждением про репрезентативность является убеждение многих, что основой репрезентативности является некоторая минимальная доля опрошенных от общей численности генеральной совокупности. Т.е. для репрезентативности нужно опросить 5%, 10%, 50% и т.д. населения (потребителей), хотя на самом деле ошибка выборки зависит от абсолютного объема выборки, а доля опрошенных, репрезентиирующих генеральную совокупность при обсуждаемых объемах генеральной совокупности (сотни тысяч или миллионы), никакой роли не играет. Формула ошибки выборки имеет нижеприведенный вид, где n это объем выборки, а N — объем генеральной совокупности. Знание математики даже на уровне 4 класса позволяет увидеть, что большое число в знаменателе делает поправку на размер генеральной совокупности при десятках тысяч и больше незначимой.
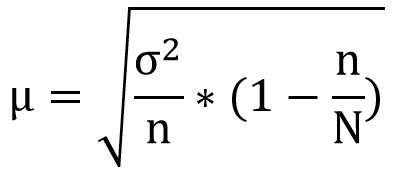
Поэтому ключевым параметром размера выборки является не размер генеральной совокупности, а разнообразие изучаемых признаков и минимальная доля опрошенных (например, потребителей конкретного бренда), внутренную структуру которых по полу, возрасту, доходу и другим социо-демографическим критериям мы собираемся анализировать. Исходя именно из известного разнообразия этих признаков (два пола, возраст в 5- или 10-летней разбивке и т..д.), в статистике постулируется, что мы можем анализировать такую группу только тогда, когда в ней не менее 60 наблюдений. Поэтому если ваш бренд имеет пенетрацию в населении 10%, то для репрезентации достаточно 600 человек, а вот если 2% то уже 3000.
Если вы считаете, что потребление вашего бренда по тем или иным причинам различается по географической «ширине» (Европейская часть, Урал, Сибирь, Дальний Восток, Кавказ и т.д.) или «глубине» (города-миллионики, большие, средние и малые города, село), то вы должны обеспечивать представленность хотя бы в 30 человек в каждой такой «ячейке» «ширина Х глубина», что делает объем необходимой выборки огромным, но содержательно вы вряд ли что-то найдете. Поэтому в практическом плане достаточно провести опрос для национальных брендов в Москве, а для региональных — в крупнейшем городе.
Если вы считаете, что потребление вашего бренда по тем или иным причинам различается по географической «ширине» (Европейская часть, Урал, Сибирь, Дальний Восток, Кавказ и т.д.) или «глубине» (города-миллионики, большие, средние и малые города, село), то вы должны обеспечивать представленность хотя бы в 30 человек в каждой такой «ячейке» «ширина Х глубина», что делает объем необходимой выборки огромным, но содержательно вы вряд ли что-то найдете. Поэтому в практическом плане достаточно провести опрос для национальных брендов в Москве, а для региональных — в крупнейшем городе.
Учитывая, что на сегодняшний день достаточно оперативной информации из точек продаж, проведение опросов для определения доли рынка смысла уже не имеют, и вообще проведение репрезентативных опросов для целей развития бренда нецелесообразно, а правильнее проведение исследований по программам «U&A(Привычки/Предпочтения)» квотных опросов основных потребительских и трендовых групп (25-40 лет для большинства товаров, более старшие возраста для медикаментов и т.д.) на основных рынках в объеме 400-800 человек.
Учитывая растущий объем оперативной рыночной информации, а также многотысячные потребительские (в России компаний Ромир и GfK) и медийные (Медиаскоп) панели, основными исследовательскими задачами проектов ad hoc становятся исследования мотивации, тестирования продуктов и рекламы («Карта восприятия», ComOverTest, BAAR), а также различные задачи, решаемые методами, по ошибке называемые «качественными». Все эти задачи можно решать и с помощью репрезентативных опросов, но если мы знаем, что потребление нашего бренда или услуги в разных социо-демографических группах различается в разы или на порядки, то такой подход является неразумным. Все эти исследования проводятся на квотных выборках, но чтобы это было информативно, следует помнить правила формирования квот и сколько же при этом опрашивать респондентов в каждой квоте.
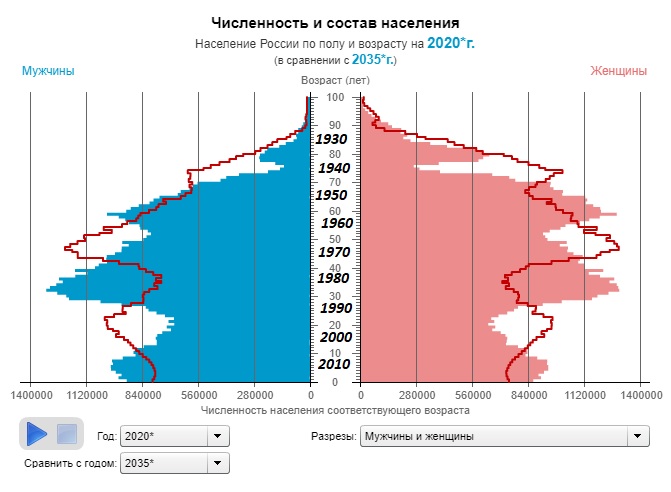
Особенность структуры российского населения такова, что у нас «возрастная пирамида» имеет вид не пирамиды, а елки, и видно, что ключевая когорта на российском рынке по численности это когорта 1980-1990 годов рождения и ее значимость на рынке будет только возрастать. Собственно говоря, мнением других на массовых рынках можно пренебречь… Безусловно, существуют рынки молодежных и возрастных (прежде всего, лекарства) товаров, а также различные специальные интересы, не сильно связанные с возрастом, но с учетом того, что и основные доходы приходятся на это поколение, эта группа становится основной для исследователей на многие годы.
В отличии от исследований U&A, исследования мотивации и тестирования рекламы являются по своим технологиям не социологическими, а психологическими, лингвистическими и физиологическими. Различия между этими исследованиями, кроме желания создать отдельную кафедру, заключаются в том, что социологи для получения «истинного среднего» задают по одному вопросу многим людям, а психологи и лингвисты для получения индивидуального «истинного значения» задают много вопросов одному (очевидно, что и большой выборке можно задать много вопросов, но это не делают по финансовым ограничениям), а психофизиологи еще и проводят всякого рода эксперименты на живых людях. В отличии от социологов, которые изучают чаще распределение 5 альтернатив ответа на вопрос, психологи, физиологи и лингвисты изучают скалярные значения. И объем выборки в исследованиях скалярных значений зависит от разнообразия (дисперсии) изучаемых признаков. Так как разнообразие психологических, физиологических и лингвистических признаков в общем случае уже известно, при проведении тех или иных исследований вы можете ориентироваться на эвристики, сформированные в этих дисциплинах.
Не вдаваясь в подробности и объяснения, просто запомните, что минимальное репрезентативное количество респондентов для любой тестовой задачи это 30 человек (а оптимальное — 60) одного пола, принадлежащих к одному поколению (размах 20-25 лет), а лучше когорте (10 лет). Если вы знаете или предполагаете, что изучаемые параметры меняются с возрастом, то вы можете расширять выборку, но при этом каждый возрастной диапазон должен иметь равную представленность, так как норма, что ошибка выборки зависит от размера выборки, а не от размера генеральной совокупности действует и тут. Поэтому для сравнения возрастной (половой и т.д.) динамики сравнимые группы должны быть равны, так как одновременно учитывать и динамику показателя в рамках непостоянной ошибки выборки задача крайне неблагодарная. При всех возможных расширениях и дополнениях, редко какая мотивационная, тестовая или лингвистическая задача требует выборок более 100 человек одного пола. Различий в результатах мотивационных, тестовых или лингвистических исследований в рамках национального рынка за 30 лет нами не обнаружено, кроме снижения лексического разнообразия по мере удаления от Москвы в ширь и/или в глубь.
Все написанное касается выборок при индивидуальном интервью. Использовать что либо из написанного для суммирования участников различных групповых извращений типа фокус-групп не позволяется, так как групповые процессы, происходящие при этом, искажают и извращают мнения участников и количество проведенных групп никак не нормирует эти искажения, а только их премножает.
Не вдаваясь в подробности и объяснения, просто запомните, что минимальное репрезентативное количество респондентов для любой тестовой задачи это 30 человек (а оптимальное — 60) одного пола, принадлежащих к одному поколению (размах 20-25 лет), а лучше когорте (10 лет). Если вы знаете или предполагаете, что изучаемые параметры меняются с возрастом, то вы можете расширять выборку, но при этом каждый возрастной диапазон должен иметь равную представленность, так как норма, что ошибка выборки зависит от размера выборки, а не от размера генеральной совокупности действует и тут. Поэтому для сравнения возрастной (половой и т.д.) динамики сравнимые группы должны быть равны, так как одновременно учитывать и динамику показателя в рамках непостоянной ошибки выборки задача крайне неблагодарная. При всех возможных расширениях и дополнениях, редко какая мотивационная, тестовая или лингвистическая задача требует выборок более 100 человек одного пола. Различий в результатах мотивационных, тестовых или лингвистических исследований в рамках национального рынка за 30 лет нами не обнаружено, кроме снижения лексического разнообразия по мере удаления от Москвы в ширь и/или в глубь.
Все написанное касается выборок при индивидуальном интервью. Использовать что либо из написанного для суммирования участников различных групповых извращений типа фокус-групп не позволяется, так как групповые процессы, происходящие при этом, искажают и извращают мнения участников и количество проведенных групп никак не нормирует эти искажения, а только их премножает.